Dabeaz
Dave Beazley's mondo computer blog. [ homepage | archive ]Wednesday, January 19, 2011
Porting Py65 (and my Superboard) to Python 3
One of my resolutions for 2011 is to write all of my software in Python 3. As a hardened Python 2 programmer, I think my initial reaction to Python 3 was lukewarm at best--it felt foreign and it made life painful in ways that I found irritating (looking at you Unicode). However, as I have used it more (and it has improved), I've really grown to like it. Most recently, I used Python 3 as the base language for my Concurrency Workshop. I have also been using it as the language for my various diabolical Superboard II projects. Last, but not least, I find myself as one of the editors working to update the O'Reilly Python Cookbook--which is going to be Python 3 only.
If you're going to use Python 3, the first thing to know is that not all libraries are going to work--not everyone has gotten around to porting their code. This means that you have to adopt a more "pioneering" mindset. In my case, I've simply decided to port the libraries that I wanted to use as I go. From a purely academic viewpoint, taking someone else's code and porting it to Python 3 is an interesting exercise. Not only will you learn a lot simply by reading someone else's code, you'll learn about all sorts of sneaky little gotchas that aren't necessarily discussed in the Python 3 porting guides.
Over the next few months, I intend to make a series of blog posts about my experiences porting different libraries. In this installment, I port Py65, a Python emulation of the 6502.
Py65 - A 6502 Emulator in Python
Py65 is a pure Python emulation of the 6502 microprocessor created by Mike Naberezny. I don't really know what motivated Mike to create an emulated 6502 in Python, but I became interested in Py65 because I suddenly had the idea that I might be able to use to create an emulated version of my old Superboard II entirely as a Python 3 program. Why, you ask? Because it would be fun. Now, stop asking silly questions--the Superboard is getting annoyed.
Py65 - A Quick Overview
One of the main features of Py65 is a 6502 machine monitor where you can load/save memory, step through programs, and try things out. For example, if you had an old 6502 ROM image sitting around, you can load it, disassemble it, and step through parts of it like this:
bash % py65mon
Py65 Monitor
PC AC XR YR SP NV-BDIZC
6502: 0000 00 00 00 ff 00110000
.load rom.bin f800
Wrote +2048 bytes from $f800 to $ffff
PC AC XR YR SP NV-BDIZC
6502: 0000 00 00 00 ff 00110000
.disassemble ff00:ff20
$ff00 d8 CLD
$ff01 a2 28 LDX #$28
$ff03 9a TXS
$ff04 a0 0a LDY #$0a
$ff06 b9 ef fe LDA $feef,Y
$ff09 99 17 02 STA $0217,Y
$ff0c 88 DEY
$ff0d d0 f7 BNE $ff06
$ff0f 20 a6 fc JSR $fca6
$ff12 8c 12 02 STY $0212
$ff15 8c 03 02 STY $0203
$ff18 8c 05 02 STY $0205
$ff1b 8c 06 02 STY $0206
$ff1e ad e0 ff LDA $ffe0
PC AC XR YR SP NV-BDIZC
6502: 0000 00 00 00 ff 00110000
.registers pc=ff00
PC AC XR YR SP NV-BDIZC
6502: ff00 00 00 00 ff 00110000
.step
$ff01 a2 28 LDX #$28
PC AC XR YR SP NV-BDIZC
6502: ff01 00 00 00 ff 00110000
.step
$ff03 9a TXS
PC AC XR YR SP NV-BDIZC
6502: ff03 00 28 00 ff 00110000
...
Of course, there are many other features described in the Py65 Documentation.
Porting Py65 to Python 3
Py65 consists of 27 .py files and about 12000 lines of code. More than half of the code consists of unit tests.
To start porting, I decided that I would just run all of the files through 2to3 to get a basic sense for what I might have to change at a syntactic level. Here is the complete output of doing that. In a nutshell, 36 lines were identified. Most of the changes were due to well-known Python 3 changes such as changed exception handling syntax, xrange() and so forth.
bash % 2to3 src
RefactoringTool: Skipping implicit fixer: buffer
RefactoringTool: Skipping implicit fixer: idioms
RefactoringTool: Skipping implicit fixer: set_literal
RefactoringTool: Skipping implicit fixer: ws_comma
--- src/py65/monitor.py (original)
+++ src/py65/monitor.py (refactored)
@@ -32,7 +32,7 @@
result = cmd.Cmd.onecmd(self, line)
except KeyboardInterrupt:
self._output("Interrupt")
- except Exception,e:
+ except Exception as e:
(file, fun, line), t, v, tbinfo = compact_traceback()
error = 'Error: %s, %s: file: %s line: %s' % (t, v, file, line)
self._output(error)
@@ -85,7 +85,7 @@
line = self._shortcuts['~'] + ' ' + line[1:]
# command shortcuts
- for shortcut, command in self._shortcuts.iteritems():
+ for shortcut, command in self._shortcuts.items():
if line == shortcut:
line = command
break
@@ -150,7 +150,7 @@
mpus = {'6502': NMOS6502, '65C02': CMOS65C02}
def available_mpus():
- mpu_list = ', '.join(mpus.keys())
+ mpu_list = ', '.join(list(mpus.keys()))
self._output("Available MPUs: %s" % mpu_list)
if args == '':
@@ -315,14 +315,14 @@
if args != '':
new = args[0].lower()
changed = False
- for name, radix in radixes.iteritems():
+ for name, radix in radixes.items():
if name[0].lower() == new:
self._address_parser.radix = radix
changed = True
if not changed:
self._output("Illegal radix: %s" % args)
- for name, radix in radixes.iteritems():
+ for name, radix in radixes.items():
if self._address_parser.radix == radix:
self._output("Default radix is %s" % name)
@@ -364,7 +364,7 @@
if len(register) == 1:
intval &= 0xFF
setattr(self._mpu, register, intval)
- except KeyError, why:
+ except KeyError as why:
self._output(why[0])
def help_cd(self, args):
@@ -374,7 +374,7 @@
def do_cd(self, args):
try:
os.chdir(args)
- except OSError, why:
+ except OSError as why:
msg = "Cannot change directory: [%d] %s" % (why[0], why[1])
self._output(msg)
self.do_pwd()
@@ -407,12 +407,12 @@
f = open(filename, 'rb')
bytes = f.read()
f.close()
- except (OSError, IOError), why:
+ except (OSError, IOError) as why:
msg = "Cannot load file: [%d] %s" % (why[0], why[1])
self._output(msg)
return
- self._fill(start, start, map(ord, bytes))
+ self._fill(start, start, list(map(ord, bytes)))
def do_save(self, args):
split = shlex.split(args)
@@ -430,7 +430,7 @@
for byte in bytes:
f.write(chr(byte))
f.close()
- except (OSError, IOError), why:
+ except (OSError, IOError) as why:
msg = "Cannot save file: [%d] %s" % (why[0], why[1])
self._output(msg)
return
@@ -455,7 +455,7 @@
return
start, end = self._address_parser.range(split[0])
- filler = map(self._address_parser.number, split[1:])
+ filler = list(map(self._address_parser.number, split[1:]))
self._fill(start, end, filler)
@@ -518,10 +518,10 @@
self._output("Display current label mappings.")
def do_show_labels(self, args):
- values = self._address_parser.labels.values()
- keys = self._address_parser.labels.keys()
+ values = list(self._address_parser.labels.values())
+ keys = list(self._address_parser.labels.keys())
- byaddress = zip(values, keys)
+ byaddress = list(zip(values, keys))
byaddress.sort()
for address, label in byaddress:
self._output("%04x: %s" % (address, label))
--- src/py65/tests/test_memory.py (original)
+++ src/py65/tests/test_memory.py (refactored)
@@ -56,7 +56,7 @@
def read_subscriber(address, value):
return 0xAB
- mem.subscribe_to_read(xrange(0xC000, 0xC001+1), read_subscriber)
+ mem.subscribe_to_read(range(0xC000, 0xC001+1), read_subscriber)
mem[0xC000] = 0xAB
mem[0xC001] = 0xAB
@@ -141,7 +141,7 @@
return 0xFF
mem.subscribe_to_write([0xC000,0xC001], write_subscriber)
- mem.write(0xC000, [0x01, 002])
+ mem.write(0xC000, [0x01, 0o02])
self.assertEqual(0x01, subject[0xC000])
self.assertEqual(0x02, subject[0xC001])
--- src/py65/tests/test_monitor.py (original)
+++ src/py65/tests/test_monitor.py (refactored)
@@ -4,7 +4,7 @@
import os
import tempfile
from py65.monitor import Monitor
-from StringIO import StringIO
+from io import StringIO
class MonitorTests(unittest.TestCase):
@@ -168,7 +168,7 @@
mon = Monitor(stdout=stdout)
mon._address_parser.labels['foo'] = 0xc000
mon.do_delete_label('foo')
- self.assertFalse(mon._address_parser.labels.has_key('foo'))
+ self.assertFalse('foo' in mon._address_parser.labels)
out = stdout.getvalue()
self.assertEqual('', out)
--- src/py65/tests/devices/test_mpu6502.py (original)
+++ src/py65/tests/devices/test_mpu6502.py (refactored)
@@ -4979,8 +4979,7 @@
self.assertEquals(0x0001, mpu.pc)
def test_decorated_addressing_modes_are_valid(self):
- valid_modes = map(lambda x: x[0],
- py65.assembler.Assembler.Addressing)
+ valid_modes = [x[0] for x in py65.assembler.Assembler.Addressing]
mpu = self._make_mpu()
for name, mode in mpu.disassemble:
self.assert_(mode in valid_modes)
@@ -5024,12 +5023,12 @@
def _make_mpu(self, *args, **kargs):
klass = self._get_target_class()
mpu = klass(*args, **kargs)
- if not kargs.has_key('memory'):
+ if 'memory' not in kargs:
mpu.memory = 0x10000 * [0xAA]
return mpu
def _get_target_class(self):
- raise NotImplementedError, "Target class not specified"
+ raise NotImplementedError("Target class not specified")
class MPUTests(unittest.TestCase, Common6502Tests):
--- src/py65/tests/utils/test_addressing.py (original)
+++ src/py65/tests/utils/test_addressing.py (refactored)
@@ -48,7 +48,7 @@
try:
parser.number('bad_label')
self.fail()
- except KeyError, why:
+ except KeyError as why:
self.assertEqual('Label not found: bad_label', why[0])
def test_number_label_hex_offset(self):
@@ -94,7 +94,7 @@
try:
parser.number('bad_label+3')
self.fail()
- except KeyError, why:
+ except KeyError as why:
self.assertEqual('Label not found: bad_label', why[0])
def test_number_truncates_address_at_maxwidth_16(self):
--- src/py65/tests/utils/test_hexdump.py (original)
+++ src/py65/tests/utils/test_hexdump.py (refactored)
@@ -27,7 +27,7 @@
try:
Loader(text)
self.fail()
- except ValueError, why:
+ except ValueError as why:
msg = 'Start address was not found in data'
self.assert_(why[0].startswith('Start address'))
@@ -36,7 +36,7 @@
try:
Loader(text)
self.fail()
- except ValueError, why:
+ except ValueError as why:
msg = 'Could not parse address: oops'
self.assertEqual(msg, why[0])
@@ -45,7 +45,7 @@
try:
Loader(text)
self.fail()
- except ValueError, why:
+ except ValueError as why:
msg = 'Expected address to be 2 bytes, got 1'
self.assertEqual(msg, why[0])
@@ -54,7 +54,7 @@
try:
Loader(text)
self.fail()
- except ValueError, why:
+ except ValueError as why:
msg = 'Expected address to be 2 bytes, got 3'
self.assertEqual(msg, why[0])
@@ -63,7 +63,7 @@
try:
Loader(text)
self.fail()
- except ValueError, why:
+ except ValueError as why:
msg = 'Non-contigous block detected. Expected next ' \
'address to be $c001, label was $c002'
self.assertEqual(msg, why[0])
@@ -73,7 +73,7 @@
try:
Loader(text)
self.fail()
- except ValueError, why:
+ except ValueError as why:
msg = 'Could not parse data: foo'
self.assertEqual(msg, why[0])
--- src/py65/utils/addressing.py (original)
+++ src/py65/utils/addressing.py (refactored)
@@ -26,7 +26,7 @@
def label_for(self, address, default=None):
"""Given an address, return the corresponding label or a default.
"""
- for label, label_address in self.labels.iteritems():
+ for label, label_address in self.labels.items():
msg = "Expected address to be 2 bytes, got %d" % (
len(addr_bytes))
- raise ValueError, msg
+ raise ValueError(msg)
address = (addr_bytes[0] << 8) + addr_bytes[1]
@@ -62,19 +62,19 @@
msg = "Non-contigous block detected. Expected next address " \
"to be $%04x, label was $%04x" % (self.current_address,
address)
- raise ValueError, msg
+ raise ValueError(msg)
def _parse_bytes(self, piece):
if self.start_address is None:
msg = "Start address was not found in data"
- raise ValueError, msg
+ raise ValueError(msg)
else:
try:
bytes = [ ord(c) for c in a2b_hex(piece) ]
except (TypeError, ValueError):
msg = "Could not parse data: %s" % piece
- raise ValueError, msg
+ raise ValueError(msg)
self.current_address += len(bytes)
self.data.extend(bytes)
RefactoringTool: Files that need to be modified:
RefactoringTool: src/py65/monitor.py
RefactoringTool: src/py65/tests/test_memory.py
RefactoringTool: src/py65/tests/test_monitor.py
RefactoringTool: src/py65/tests/devices/test_mpu6502.py
RefactoringTool: src/py65/tests/utils/test_addressing.py
RefactoringTool: src/py65/tests/utils/test_hexdump.py
RefactoringTool: src/py65/utils/addressing.py
RefactoringTool: src/py65/utils/hexdump.py
Not seeing anything too critical, I decided to invoke 2to3 -w to simply patch all of the code. However, I must emphasize--using 2to3 is almost never enough to make a Python 3 port. In the next few parts, I discuss a few tricky porting problems encountered in making the new library work. This is by no means an exhaustive list.
Python 3 Porting Issue : Exception Indexing
In several places, Py65 performs an indexed lookup on exception values. For example, consider this fragment:
try:
f = open("somebadfile")
except IOError as why:
msg = "Cannot open file: [%d] %s" % (why[0], why[1])
print(msg)
If you try this code in Python 2, it works. However, if you try it in Python 3, you will get an TypeError crash like this:
Traceback (most recent call last): File "<stdin>", line 2, in <module> IOError: [Errno 2] No such file or directory: 'badfile' During handling of the above exception, another exception occurred: Traceback (most recent call last): File "<stdin>", line 4, in <module> TypeError: 'IOError' object is not subscriptable
Under the covers, exceptions hold their value in an args tuple. In Python 2, operations such as why[0] and why[1] would simply return why.args[0] and why.args[1]. This no longer works in Python 3 so you can't rely on it. A better fix is to either refer to args directly or to use the documented exception attributes. For example:
try:
f = open("somebadfile")
except IOError as why:
msg = "Cannot open file: [%d] %s" % (why.errno, why.strerror)
print(msg)
In Py65, I identified 12 lines where exceptions are indexed in this manner. Most of those changes were in unit tests that checked for specific exception messages and error codes.
While we're on the subject of exceptions, it's also worth noting that the scope of the why variable in the above example is different in Python 3. Specifically, exception variables are only defined for code inside the except block. In Python 2, such variables persists after the try-except statement.
Python 3 Porting Issue : Overloaded Slicing
One of the objects defined by Py65 is an observable memory buffer. The precise implementation is not so important, but it's programmed to be a list-like object that supports both indexing and slicing, but with the ability to invoke registered observer functions on user-specified indices (see the project at the end of the post for an example).
In Python 2, you could use different methods for indexing and slicing by implementing __getitem__() and __getslice__() like this:
class ListLike:
def __getitem__(self,n):
print("getitem",n)
def __getslice__(self,start,stop=None,step=None):
print("getslice", start,stop,step)
The only problem is that in Python 3, __getslice__() no longer exists as a special method (in fact, it's deprecated in Python 2 as well, but is still supported for backwards compatibility). So, if you try the following example, you'll see __getitem__() being called for both indexing and slicing. Here is what happens:
>>> s = ListLike() >>> s[2] getitem 2 >>> s[2:4] getitem slice(2, 4, None) >>>
Unless you've programmed __getitem__() specifically to look for slice objects, you will run into trouble. For example, when trying Py65, I started getting all sorts of errors about incorrect use of slice objects. However, here's a little bit of code that solves that problem:
class ListLike:
def __getitem__(self,n):
if isinstance(n,slice):
return [self[i] for i in range(*n.indices(len(self)))]
# Return item n
...
Or, if you're a little more sneaky, you might use itertools:
class ListLike:
def __getitem__(self,n):
if isinstance(n,slice):
return list(itertools.islice(self,*n.indices(len(self))))
# Return item n
...
For slices, the value passed to __getitem__() will be a slice object. You can create these yourself.
>>> n = slice(2,4) >>> n slice(2, 4, None) >>>
The indices(size) method of a slice returns a tuple (start, stop, step) that you can use should you decide to iterate over the slice using range() or some other function. For example:
>>> n.indices(100) (2, 4, 1) >>>
You can use this result as input to range() to generate the needed sequence of indices associated with the slice.
Python 3 Porting Issue: Treating bytes as character arrays
If you perform any kind of binary I/O in Python 3, be aware that data will be read as bytes objects and that those objects do not have the same behavior as strings.
Consider this code fragment from Py65, in particular, the parts highlighted in red.
try:
f = open(filename, 'rb')
bytes = f.read()
f.close()
except (OSError, IOError) as why:
msg = "Cannot load file: [%d] %s" % (why[0], why[1])
self._output(msg)
return
self._fill(start, start, list(map(ord, bytes)))
First complaint--don't use bytes as the name of a variable. bytes is now the name of a built-in type. However, that's not the problem here. Instead, the problem is with the map() operation at the end. Here is what happens in Python 2:
>>> s = "Hello" >>> list(map(ord,s)) [72, 101, 108, 108, 111] >>>
If you try it in Python 3, you get an error:
>>> s = b"Hello" >>> list(map(ord,s)) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: ord() expected string of length 1, but int found >>>
What's happening here? Well, the answer is simple--bytes objects in Python 3 are already treated as arrays as integers so the extra conversion using ord() isn't needed. For example:
>>> s = b"Hello" >>> s[0] 72 >>> s[1] 101 >>> s[2] 108 >>>
In the case of the above example, you can replace list(map(ord,bytes)) with list(bytes) or maybe even just bytes as it is already considered to be an array of integer values.
Porting Summary
All told, I don't think I spent more than about an hour porting Py65 so that I could use it with Python 3. As part of this work, I must emphasize that I ported all of the supplied unit tests and also ran them under Python 3 until all reported test failures were resolved. Although I can't claim that it is bug-free, it was good enough to do the project described next.
Py65 Project: Creating an Emulated Superboard II
In previous blog posts, I've described a couple of projects involving my old Superboard II system--my first computer. Here is a picture of it.

To make an emulator, you need to know details about the underlying hardware including memory map, ROMs, and hardware devices. For this, I referred to the Superboard II memory map taken straight from its user manual. Here it is:

To capture the ROM images, I wrote two simple BASIC program to dump the ROM data out of the cassette port. For example, like this:
5 REM DUMP THE BASIC ROM TO CASSETTE 10 FOR X = 40960 TO 49151 20 WAIT 61440, 2 30 B = PEEK(X) 40 POKE 61441, B 50 NEXT
By recording the audio stream using Audicity on my Mac and decoding the resulting WAV files using the Python scripts described in a previous post I was able to capture both the 8K BASIC ROM and 2K system ROM. I put these in files basic.bin and rom.bin.
Next up, you need to understand how the hardware devices work such as the Video RAM, polled keyboard, and 6850 ACIA serial port. For example, you need to wrap your brain around everything that is going on this figure:
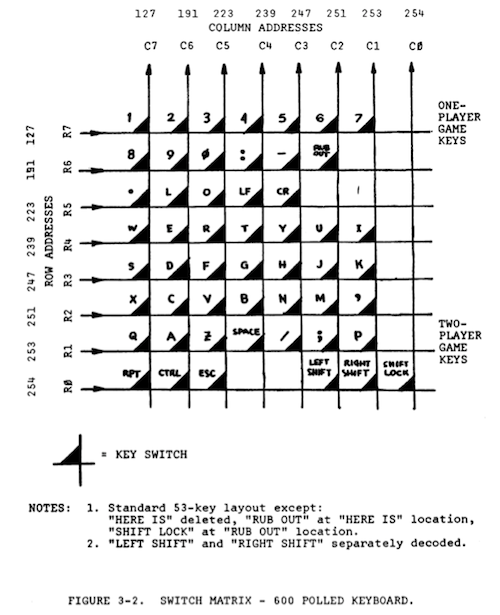
Once you understand that, you're ready to make an emulation. To do it, you need to address two basic problems. First, you need to load the captured ROM images. That's the easy part. Next, you need to install observer functions on the memory addresses mapped to different hardware devices and make those functions immitate the actual hardware. That's the tricky bit.
Here is an example of doing just that. The most notable part of this code is found in the map_hardware() function that maps functions to certain memory addresses. If you look at these functions, you can see how they capture memory access and use that to emulate hardware devices. Of course, figuring out all of the subtle details of the Superboard II hardware is left as an exercise to the reader:
#!/usr/bin/env python3 -u
import py65.monitor
import sys
import select
# Write to a specific video address (using VT100 cursor control)
def video_output(address,value):
row = (address - 0xd000) // 32
column = address % 32
sys.stdout.write(('\x1b[7m\x1b[<%d>;<%d>H' % (row,column)) + chr(value) + '\x1b[0m')
sys.stdout.flush()
# Keyboard mapping table (for polled keyboard)
keymap = {
b'\x00' : {254:254, 253:255, 251:255, 247:255, 239:255, 223:255, 191:255, 127:255},
b'\r' : {254:254, 223:247},
b'\n' : {254:254, 223:247},
b' ' : {254:254, 253:239},
b'/' : {254:254, 253:247},
b';' : {254:254, 253:251},
b':' : {254:254, 191:239},
b'-' : {254:254, 191:247},
b'.' : {254:254, 223:127},
b',' : {254:254, 251:253},
b'A' : {254:254, 253:191},
b'B' : {254:254, 251:239},
b'C' : {254:254, 251:191},
b'D' : {254:254, 247:191},
b'E' : {254:254, 239:191},
b'F' : {254:254, 247:223},
b'G' : {254:254, 247:239},
b'H' : {254:254, 247:247},
b'I' : {254:254, 239:253},
b'J' : {254:254, 247:251},
b'K' : {254:254, 247:253},
b'L' : {254:254, 223:191},
b'M' : {254:254, 251:251},
b'N' : {254:254, 251:247},
b'O' : {254:254, 223:223},
b'P' : {254:254, 253:253},
b'Q' : {254:254, 253:127},
b'R' : {254:254, 239:223},
b'S' : {254:254, 247:127},
b'T' : {254:254, 239:239},
b'U' : {254:254, 239:251},
b'V' : {254:254, 251:223},
b'W' : {254:254, 239:127},
b'X' : {254:254, 251:127},
b'Y' : {254:254, 237:247},
b'Z' : {254:254, 253:223},
b'1' : {254:254, 127:127},
b'2' : {254:254, 127:191},
b'3' : {254:254, 127:223},
b'4' : {254:254, 127:239},
b'5' : {254:254, 127:247},
b'6' : {254:254, 127:251},
b'7' : {254:254, 127:253},
b'8' : {254:254, 191:127},
b'9' : {254:254, 191:191},
b'0' : {254:254, 191:223},
b'!' : {254:252, 127:127},
b'"' : {254:252, 127:191},
b'#' : {254:252, 127:223},
b'$' : {254:252, 127:239},
b'%' : {254:252, 127:247},
b'&' : {254:252, 127:251},
b"'" : {254:252, 127:254},
b'(' : {254:252, 191:127},
b')' : {254:252, 191:191},
b'*' : {254:252, 191:239},
b'=' : {254:252, 191:247},
b'>' : {254:252, 223:127},
b'<' : {254:252, 251:253},
b'?' : {254:252, 253:247},
b'+' : {254:252, 253:251},
}
# Raw file underlying stdin
raw_stdin = sys.stdin.buffer.raw
# State about what's being polled
kb_row = 0
kb_current = keymap[b'\x00']
kb_count = 0
# Read the row values for the polled row
def keyboard_read(address):
global kb_count, kb_current
if kb_count > 0:
kb_count -= 1
if kb_count < 5:
# Simulate key-release
kb_current = keymap[b'\x00']
else:
kb_current = keymap[b'\x00']
if kb_row == 254:
# Poll stdin to see any input
r,w,e = select.select([raw_stdin],[],[],0)
if r:
keyboard_press(raw_stdin.read(1))
return kb_current.get(kb_row,255)
# Set the current keyboard poll row
def keyboard_write(address, val):
global kb_row
kb_row = val
# Initiate a keypress
def keyboard_press(ch):
global kb_count, kb_current
if ch in keymap:
kb_current = keymap[ch]
kb_count = 30
def map_hardware(m):
# Video RAM at 0xd000-xd400
m.subscribe_to_write(range(0xd000,0xd400),video_output)
# Monitor the polled keyboard port
m.subscribe_to_read([0xdf00], keyboard_read)
m.subscribe_to_write([0xdf00], keyboard_write)
# Bad memory address to force end to memory check
m.subscribe_to_read([0x8000], lambda x: 0)
def main(args=None):
c = py65.monitor.Monitor()
map_hardware(c._mpu.memory)
try:
import readline
except ImportError:
pass
# Load the ROMs and boot
c.onecmd("load rom.bin f800")
c.onecmd("load basic.bin a000")
c.onecmd("goto ff00")
try:
c.onecmd('version')
c.cmdloop()
except KeyboardInterrupt:
c._output('')
if __name__ == "__main__":
main()
Running the Emulation
Running the emulation in a VT100 compatible terminal window, you'll get output that looks like this. Yep, that's my Superboard II running up in the upper left corner of the terminal window (click on the image to see a video):
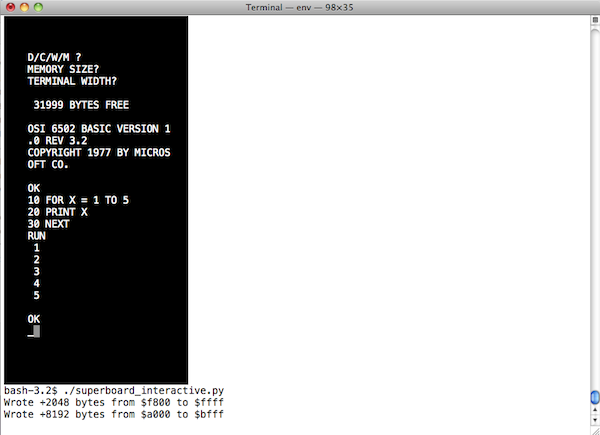
Admittedly, it's kind of a hack, but then again, that's the whole point.
Final Words
I've put my modified Py65 code online at http://github.com/dabeaz/py65. The distribution also includes a slightly different emulation example that allows you to telnet to an emulated Superboard.
I gave a talk about this at the January 13, 2011 meeting of Chipy. Check out the video.
Archives
08/01/2009 - 09/01/2009 09/01/2009 - 10/01/2009 10/01/2009 - 11/01/2009 11/01/2009 - 12/01/2009 12/01/2009 - 01/01/2010 01/01/2010 - 02/01/2010 02/01/2010 - 03/01/2010 04/01/2010 - 05/01/2010 05/01/2010 - 06/01/2010 07/01/2010 - 08/01/2010 08/01/2010 - 09/01/2010 09/01/2010 - 10/01/2010 12/01/2010 - 01/01/2011 01/01/2011 - 02/01/2011 02/01/2011 - 03/01/2011 03/01/2011 - 04/01/2011 04/01/2011 - 05/01/2011 05/01/2011 - 06/01/2011 08/01/2011 - 09/01/2011 09/01/2011 - 10/01/2011 12/01/2011 - 01/01/2012 01/01/2012 - 02/01/2012 02/01/2012 - 03/01/2012 03/01/2012 - 04/01/2012 07/01/2012 - 08/01/2012 01/01/2013 - 02/01/2013 03/01/2013 - 04/01/2013 06/01/2014 - 07/01/2014 09/01/2014 - 10/01/2014
![]()
Subscribe to Posts [Atom]